

VoiceFox is simple when it works well. Hold a hotkey, say a sentence, let go, and the words appear wherever your cursor is. No cloud round trip. No meeting transcript service. Just local dictation on an M-series Mac.
When it feels slow, though, the magic breaks. A few months ago VoiceFox was closer to 2.4 seconds end to end. That does not sound catastrophic until you try to dictate into a text box and wait. The pause is just long enough for your brain to ask, "Did it hear me?"
This is how we cut that wait down to about 1.0 to 1.5 seconds. It was not one clever optimization. It was a bunch of small measurements, a few Codex runs, and one important lesson: the benchmark has to protect the thing users actually care about.
What VoiceFox is
VoiceFox is push-to-talk dictation for Apple Silicon Macs. The model is Parakeet-MLX running locally through MLX. Around that model is a practical little workflow: capture audio, transcribe it, clean up custom vocabulary, put the text on the clipboard, paste it into the active app, and then get out of the way.
The pipeline is simple enough to fit in your head: hotkey down, audio capture, hotkey release, model inference, decode, vocabulary replacement, clipboard write, synthetic paste. VoiceFox is also intentionally a small script. That made it a good place to try autoresearch because Codex had one main file to work on, voicefox.py, and we could measure one layer at a time.
First, measure the waiting
The first pass was not fancy. We added profiling and asked a boring question: where does the time go?
That audit found the kind of delays that hide in small apps. VoiceFox was writing captured audio to a temporary WAV file and reading it back before inference. It had fixed sleeps in the paste path. It had capture settings that were fine for correctness but not tuned for speed. It had decode settings that were conservative because nobody had proved a lower cap was safe.
| Change | Measured effect | Why it mattered |
|---|---|---|
| Direct audio processing | about 330 ms saved | VoiceFox no longer writes every capture to a temporary WAV file before feeding MLX. |
| Low-latency capture | about 50 to 100 ms saved | Recording overhead dropped without changing the interaction model. |
| Paste timing | about 160 ms saved | Fixed sleeps and clipboard sequencing were trimmed after profiling showed the floor. |
| Decode controls | about 50 to 100 ms saved | Parakeet decode caps were tuned only after a real-voice accuracy gate existed. |
Those changes account for roughly 540 to 590 ms of the improvement. Good start. But this is also where you can fool yourself. A latency benchmark will happily reward you for deleting safety. VoiceFox needed to get faster, but it still had to paste reliably and transcribe accurately.
Then Codex tried small changes
The first autoresearch loop went after post-submit latency: the time after VoiceFox has text and before that text lands in the active app. This was a nice starter problem. It was narrow, fast to measure, and mostly isolated from speech recognition quality.
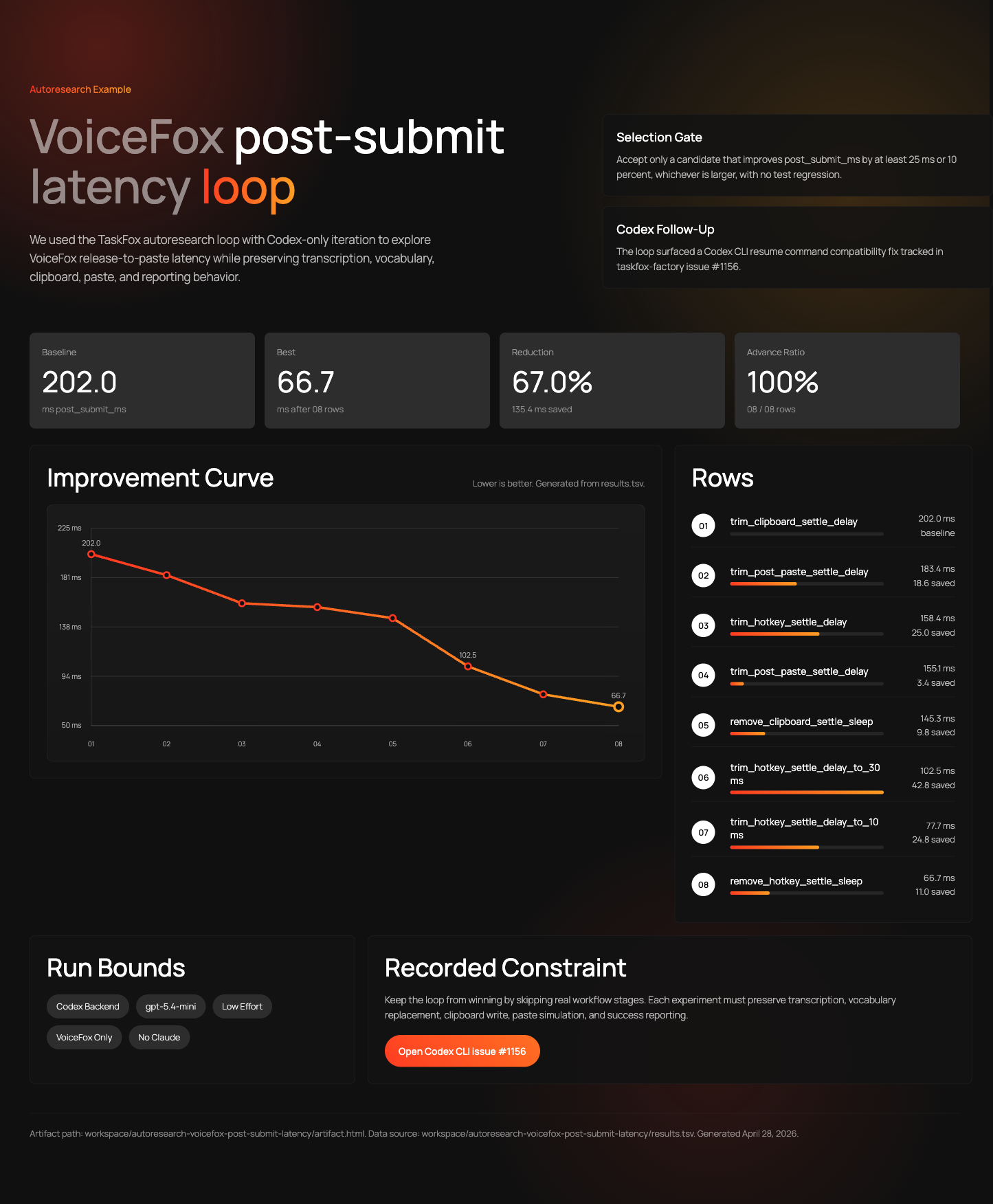
results.tsv on April 28, 2026. This is the kind of evidence we wanted in the article: the actual run, not a mockup.The run above used a Codex backend with gpt-5.4-mini at low effort. It just kept making tiny changes and measuring them. The baseline row was 202.0 ms. The best row was 66.7 ms after eight rows, a 67.0 percent reduction on that specific metric.
That was exciting, but it also exposed the first trap: a benchmark can be too narrow. The post-submit loop could find real paste-path wins. It could not tell us whether a faster decoder was cutting off words. For that, we needed to move closer to the model.
The next benchmark was too easy to trust
The next loop targeted the real speech-to-text path. We started with one real audio clip because it was fast and convenient. Codex gpt-5.4-mini at high effort did the first big search. It reached the requested 50 experiment rows and found a promising stack: faster audio handoff, a reused decoding config, a lower symbol cap, and a few small cleanup wins around the model call.
Then we handed the same lane to stronger Codex runs. gpt-5.5 at medium effort extended the loop past row 50. It did not beat the current best. A final gpt-5.5 xhigh pass tried deeper MLX ideas. None advanced. One crashed and was reverted.
Single-fixture loop: baseline median 233.434 ms, best loop median 178.041 ms, 65 experiment rows plus baseline, 6 advances, 57 discards, 2 crashes.
That looked like a clean win. Then confirmation made it less tidy, which is exactly what confirmation is for. Pre-review reruns showed a 216.994 ms median, about 7.0 percent better than the 233.434 ms baseline. Post-review reruns were noisier at 225.608 ms, while a longer 21-iteration check landed at 190.755 ms. Still useful, but not as simple as "the loop found 23.7 percent and we shipped it."
This was the second trap: a single fixture is a leaderboard, not a product test. It can tell you a candidate is interesting. It cannot tell you the app still works for the variety of things a person actually says.
So we recorded a real voice corpus
So Codex built a small recording program: scripts/record_voicefox_corpus.py. The job of that program was deliberately plain. Show Casey a short transcript, wait for him to read it aloud, record mono 16 kHz PCM WAV, then write a manifest that pairs the audio file with the expected transcript.
The corpus came from a very normal place: Casey's car, in a parking lot. The laptop was tethered to the internet through his phone. So the benchmark was not born in a studio or a lab. It came from the same kind of imperfect setup people actually use: laptop, mic, parking lot, phone hotspot, and Codex steadily working through the problem in the background.
The prompts were not random sentences. They were small, practical phrases that resemble actual dictation work:
- short commands such as "Open the build log" and "Save this note"
- normal dictation such as "Please summarize the pull request and mention any risky assumptions"
- fast speech, punctuation-like speech, long numbers, proper nouns, dense run-on phrases, quiet voice, and one longer dictation sample
The finished corpus had 16 fixtures. The audio stays private because it is real voice, but the shape of the corpus is visible in the repo. The recorder writes audio/*.wav and a manifest.json with id, path, category, and expected fields. That was enough structure for the benchmark to load the same clips every time and compare output against the expected transcript.
The gate made latency honest
The eval surface was bench_real_stt_corpus.py. It loads the local Parakeet model once, runs every WAV fixture, records latency samples, and then applies accuracy gates. The primary loop score is intentionally easy to understand:
gated_score_ms = median_ms + 0.25 * p95_msMedian latency captures the normal case. p95 adds a penalty for spiky behavior. Then comes the big rule: if any fixture fails accuracy, the score becomes 999999.0. A bad transcript cannot hide behind a faster median.
| Gate | Failure condition |
|---|---|
| Empty output | Any blank transcription fails. |
| Character similarity | Below max(0.90, baseline fixture similarity - 0.01) fails. |
| Word error rate | Above min(0.25, baseline fixture WER + 0.03) fails. |
| Output length | Below 85 percent of the baseline output length fails. |
Character similarity is a rough "does this look like the expected sentence?" score. Word error rate is exactly what it sounds like: how many words are wrong, missing, or inserted. Output length catches the especially sneaky failure where the model returns a short, plausible fragment and calls it done.
This gate turned the search from "make the number smaller" into "make the number smaller without breaking dictation." The loop could change decode and inference settings in voicefox.py. It could not edit the recordings, the benchmark, paste behavior, model files, dependencies, or vocabulary.
The run we trusted
The corpus-gated run produced 51 total experiment rows including baseline. Only two rows advanced. Forty-eight were discarded. The best loop row was retry_tiny_short_cap_transcripts, which used a lower decode cap for short audio and retried once with a safer cap if the first transcript looked suspiciously short.
Accuracy-gated decode loop
Lower gated_score_ms is better. Any accuracy failure becomes 999999.0.
The loop report looked stronger than the final retained result: 394.7 down to 307.6, a provisional 22.1 percent improvement. This is the point where it would have been easy to stop too early. Instead, Codex reran the retained candidate against the original baseline and two close challengers, then compared median-of-three confirmation scores. The guarded retry stayed ahead, but the confirmed gap was smaller. That is exactly why the confirmation step mattered.
The accepted change is also easy to state. For short audio, VoiceFox tries a faster decode setting first. If the transcript comes back suspiciously short, it retries once with the safer general setting. In code, that means a short-audio cap of 4, a general cap of 5, a short-audio threshold of 7 seconds, and a retry floor of 10 characters.
The rejected rows mattered too
The rejected rows matter as much as the accepted row. The loop tried lower caps, alternative retry floors, and nearby decode configurations. Some were faster in isolation. They did not beat the gated score after the full corpus ran, or they looked less convincing once compared against the baseline and close challengers.
This is where the VoiceFox run became more than an "AI optimized my code" story. Codex was not allowed to keep a change just because one number got smaller. The change had to survive the corpus. Then it had to survive repeated confirmation against baseline. Then the tests had to cover the new short-audio path so the behavior could not disappear later.
What I take from it
The reusable pattern is small. If you have the following, you can run a useful autoresearch loop:
- A piece of code or a setting you are willing to let Codex change
- A repeatable test that prints a number
- A rule that says when a result is not acceptable
The gate is the part that gets skipped most often. Without a gate, the loop becomes a hill climb that optimizes the visible metric and silently regresses a property the metric did not capture. With a gate, the loop can still move quickly, but it cannot win by cheating.
The 16-fixture VoiceFox corpus is intentionally small. A bigger corpus would catch more failure modes, but it would slow the loop and reduce the number of ideas Codex could test. For this problem, the better trade was a small corpus with sharp gates: enough clips to catch short commands, fast speech, numbers, proper nouns, quiet speech, and dense dictation, but fast enough to run repeatedly.
The pattern also makes incidents auditable. When the symbol-cap value gets bumped a year from now, the loop will run, and the gates will refuse the bump if the short-clip case still degrades. The decision lives in the eval, not in someone's memory.
Coda
The 540 to 590 ms improvement is real, but the better lesson is how it was earned. The post-submit loop produced a satisfying improvement curve. The single-fixture STT loop produced a tempting leaderboard. The corpus loop produced the result we could actually trust: a smaller confirmed latency win, with zero accuracy failures and unchanged accuracy metrics across the confirmation runs.
If you build AI tools that run locally, the most useful thing in this article is probably not the loop itself. It is the discipline around the loop. Pick the metric. Build the fixture set. Name the gates. Show the result rows. Then let the autoresearcher move quickly inside that boundary.
VoiceFox is in the Lab. The latency audit and the autoresearch loop spec live in the project repo; the autoresearcher pattern itself is generic enough that it has its own article waiting to be written about non-VoiceFox uses.